This is a blog about programming and technology maintained by Vinney Cavallo.
Posts
-
Jul 30, 2020 How To Expand the Entire Component Tree in Vue DevTools
Clicking on each subsequent expansion arrow is folly.

-
Jun 27, 2018 Using webpack-dev-server and HMR on a Remote Machine/VPS
Setting up webpack-dev-server HMR on a remote machine to work over nginx isn’t fun - but USING IT IS!
-
Dec 6, 2017 Setting up Middleman and Tailwind CSS

Middleman and Tailwind make landing pages a breeze (get it?). Here’s how to get them to work together!
-
Mar 1, 2017 How to beat the Impostor Syndrome
Presenting a cure for Impostor Syndrome - in the form of a simple CRUD app that got shoved out of the nest before it thought it was ready. You could say it had a touch of impostor syndrome itself.
-
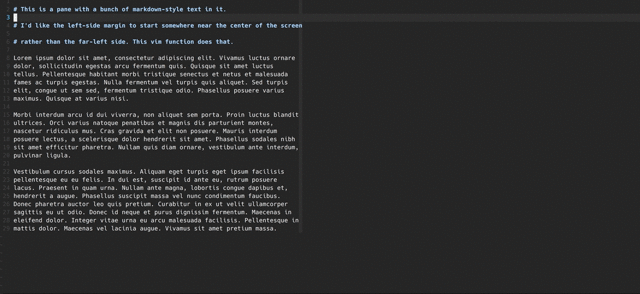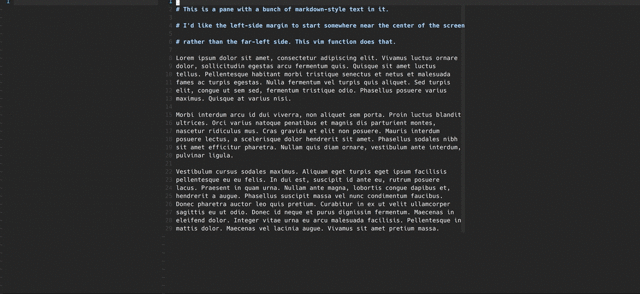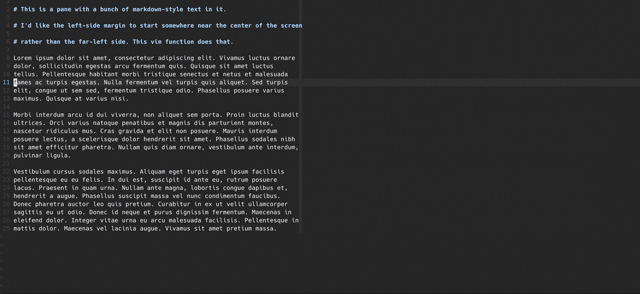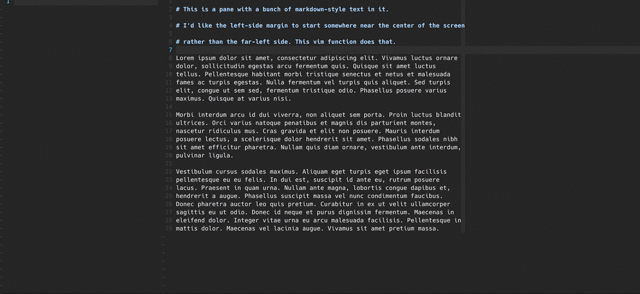
Feb 28, 2017 How to center a pane in vim
Centering a vim pane within a full-screen terminal window is really nice when focusing on writing a single buffer of non-code prose. Here’s how to do it.
-
Aug 29, 2015 A Way To Share Bash Scripts Between Machines
Or: How I thought I invented the “dotfiles” and “scripts” repo idea… Read on if you like having access to the same command-line tools on different machines.
-
Oct 15, 2013 Understanding Recursion

Learn yourself a bit about recursion!
-
Oct 7, 2013 Overview Test-Driven Development
A little overview of TDD, written at a time when I had just learned about it myself.
subscribe via RSS